
How LLMs boosted our bank statement parsing coverage by up to 5x
Table of Contents
[ show ]- Loading table of contents...
Each field on a bank statement — from the beginning balance to the account number to the statement dates — helps establish a clear financial picture of an applicant. Parsing these details accurately is critical for powering our customers’ decision-making and enabling effective fraud detection.
At Inscribe, we’ve always prioritized high-quality document understanding. That means evolving our systems as technology improves. Most recently, we transitioned our entire bank statement parsing flow to use large language models (LLMs). Every bank statement that comes through Inscribe is now parsed using a model designed to handle the complexity and variability of real-world financial documents.
Parsing at scale: why bank statements are hard
Bank statements are far from standardized. They vary widely across financial institutions, with differences in layout, terminology, language, and structure. Some documents are stitched together from multiple statements. Others contain information for more than one account. Many include cover pages or inconsistent formatting.
Despite this variety, customers expect clean, reliable structured data from every document. They depend on fields like names, dates, balances, and account numbers to power underwriting, onboarding, and compliance workflows — and these same fields fuel our fraud detection systems. Parsing them accurately is essential to everything that follows.
A step forward with LLM-powered parsing
To deliver even more reliable data at scale, we built and rolled out a new parsing system powered by LLMs. This system is now used for every bank statement we process.
LLMs are a natural fit for this challenge. They can understand documents written in many languages and adapt to variations in layout and formatting. That flexibility makes them more resilient to the edge cases and inconsistencies common in financial documents.
The new parser focuses on the key fields our customers care about most:
- Customer name
- Customer address
- Account number
- Account name
- Statement beginning and end dates
- Beginning and ending balances
Accurately parsing these details not only supports customer workflows but also strengthens downstream fraud detection. Just as importantly, the LLM-based approach makes it easier to expand field coverage in the future without extensive manual effort or retraining.
Powering better fraud detection
Many of our most effective detectors rely directly on parsed bank statement outputs. Examples include:
- Transactions Match Balances — compares parsed transactions and balances for inconsistencies.
- Repeat Account Number — flags reused account numbers across applications with different identities.
- Name Format Anomaly — detects suspicious name formatting.
- Date Format Anomaly — spots irregular date formats.
- Copycat Text — identifies repeated text across documents.
When parsing is more complete and consistent, these detectors perform better. They surface stronger fraud signals with fewer false positives — leading to faster reviews, clearer outcomes, and greater trust in the results.
The impact so far
Since rolling out the LLM-based parsing system, we’ve seen significant improvements across the board:
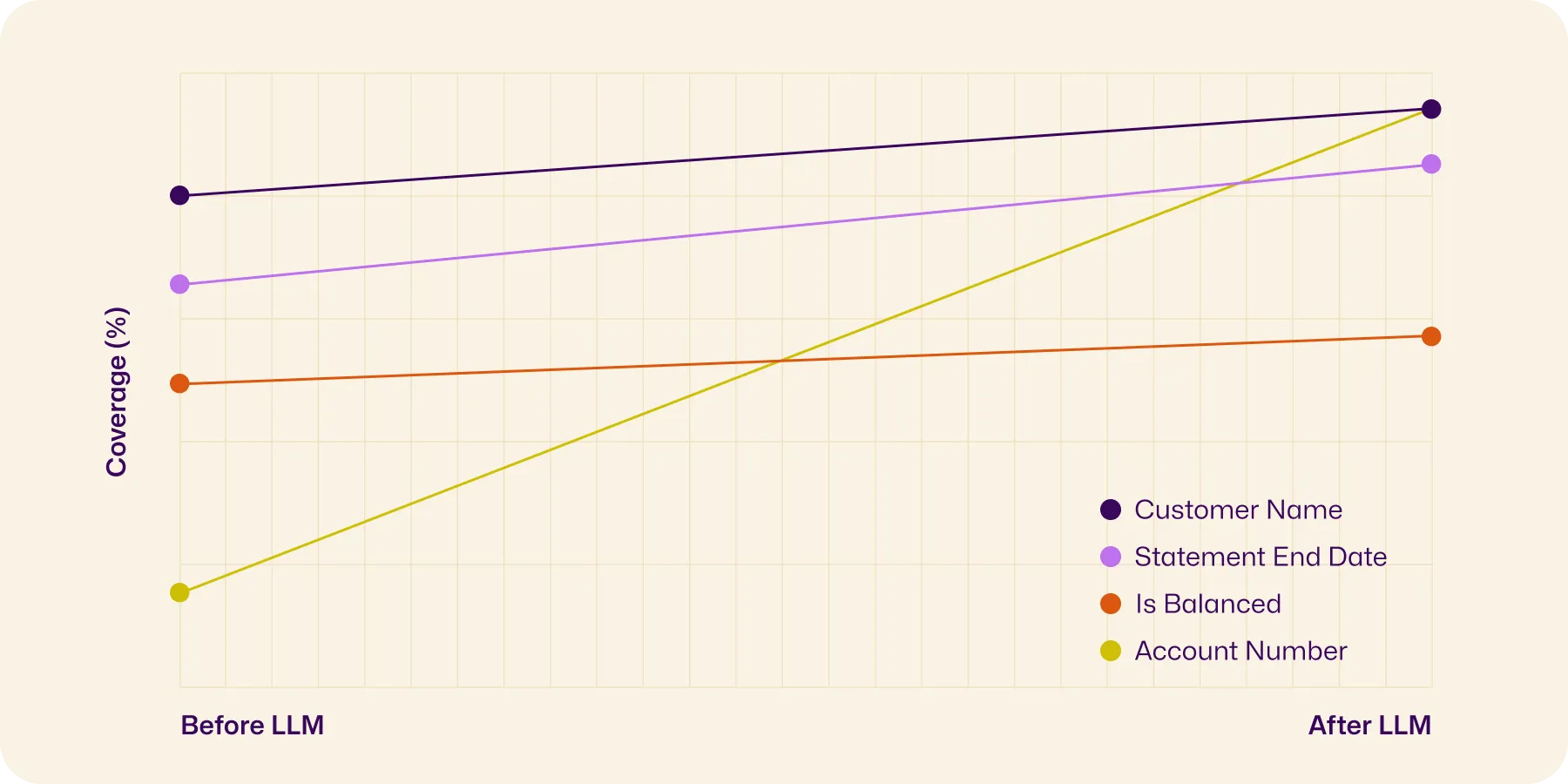
Non-English bank statements:
- Account number coverage: 18% → 94%
- Customer name coverage: 80% → 94%
- Statement end date coverage: 64% → 86%
- “Is balanced” rate: 50% → 57%
English bank statements:These improvements have already reduced false positives in fraud detection and made parsing outputs more reliable for customer workflows.
- Account number coverage: 87% → 98%
- Plus consistent gains across statement dates and balances
What’s next
This rollout is an important step forward in our mission to make fraud detection faster, smarter, and more accurate. With LLMs at the core of our document understanding systems, we can support more document types, adapt more quickly to new customer needs, and continue setting a high bar for structured output quality and reliability.
Parsing is just the beginning. When we understand what a document is saying, we’re better equipped to detect when something isn’t quite right — and that helps our customers catch fraud with confidence.
If you want to dive deeper into any of the updates mentioned here, request time with an AI expert from our team.
About the author
Louise O'Connor is a Senior Machine Learning Engineer at Inscribe AI, where she leads a dynamic team focused on developing state-of-the-art risk models for fintechs, banks, and lenders. With a extensive expertise in AI and machine learning, Louise excels in leveraging advanced techniques to solve complex problems. Her impressive background includes a role in Optum's Advanced Technology Collaborative, where she gained experience in cutting-edge technologies and research. This unique blend of skills and experience positions Louise as a standout leader in the field, dedicated to pushing the boundaries of what’s possible in machine learning and AI.
What will our AI Agents find in your documents?
Start your free trial to catch more fraud, faster.