
What “explainable AI” actually means and how to tell If a fraud vendor has it
Table of Contents
[ show ]- Loading table of contents...
Every fraud vendor selling AI to financial institutions right now has a version of the same pitch: our system is powerful, fast, and accurate.
What they don't always tell you is whether you'll ever understand why it made a decision.
That gap matters more than most people realize. In financial services, decisions have consequences. A loan gets approved or denied. A member gets flagged for fraud review. An application gets escalated. Each of those outcomes needs to be documented, auditable, and defensible, both to regulators and to the people making the call.
So here's the question I'd encourage every risk leader to ask before they buy: When your AI makes a decision, can your team actually explain it?
The black box problem in AI fraud detection
Most legacy fraud detection systems operate as black boxes. A risk score comes out. Maybe a reason code accompanies it. But the reasoning that produced that score, the specific observations, the logic, the sequence of checks, is invisible.
This creates a few practical problems:
First, your team can't learn from it. If analysts can't see why something was flagged, they can't develop intuition, build better workflows, or spot when the model is wrong.
Second, it makes compliance harder. Risk ops teams need to document their decisions, and "the model said so" isn't documentation.
Third, it erodes trust. When something gets flagged and the only explanation is a score, reviewers have to choose between blindly trusting the system or ignoring it entirely.
Human analysts have the same problem, by the way. When a seasoned underwriter makes a call, they often can't fully articulate the reasoning either. They've pattern-matched from experience, but writing it down after the fact takes time and is inherently reconstructed. AI can actually do better here, if it's designed to.
What genuine explainability looks like
There's a difference between a system that produces an explanation and a system that reasons out loud.
A system that produces an explanation is doing something like summarizing after the fact: "This document was flagged because of a metadata anomaly." That's better than nothing, but it's still a compressed output. The actual reasoning is hidden.
A system that reasons out loud shows you its work as it goes. Think of it like the difference between a student who hands in an answer and a student who shows every step of the proof. The second student's work is auditable. You can follow the logic, find the error, or confirm the conclusion independently.
At Inscribe, we've been building toward this second model. When our AI Agents analyze a document, the system shows you what it's doing at each step: which documents it's reading, which external sources it's checking, which tools it's calling. The reasoning is generated live, in front of the user. And the agent validates its own responses before surfacing them, so the output isn't just fluent. It's checked.
That's what we mean when we talk about explainability: proofs of work, not just summaries.
A note on non-determinism (it's not a bug)
One of the most common concerns I hear from technical buyers is about consistency. If LLMs are probabilistic, if they interpret information a little differently each time, how can you trust them for high-stakes decisions?
It's a fair question, and it deserves a direct answer.
Large language models do have what's called a temperature parameter, which governs how creative or variable their outputs are. For fraud detection, we set temperature to zero. That means the system is configured for maximum consistency: given the same inputs, it is more likely to produce similar conclusions. The order of analysis might vary slightly, the way a human analyst might approach the same case from different angles, but the underlying observations and reasoning remain logically consistent.
There's a separate point worth making here, though: an LLM's ability to generalize is a feature. Systems that generalize better, that don't just pattern-match on cases they've seen before, are more capable of finding new fraud patterns they've never been trained on specifically. The same capability that makes a reasoning model less rigid is what makes it more adaptive. That's worth understanding when you're evaluating vendors.
How to evaluate AI vendors on explainability (plus 4 questions to ask)
When you're evaluating an AI vendor on explainability, I'd break it down into a few workstreams.
1. Is there a human in the loop?
Is the system making recommendations or fully automated decisions? The explainability requirements are different in each case. A human-in-the-loop system has more tolerance for ambiguity, because a trained analyst can weigh the AI's findings against their own judgment. A fully automated system has to earn more trust on its own, which means the reasoning needs to be more robust and more transparent.
2. Can it generate audit-ready documentation for every decision?
Can the system generate the documentation required for every decision it makes? Not summaries. Actual records. In regulated environments, this isn't optional. If a vendor can't answer this clearly, that's a signal worth taking seriously.
3. Is explainability proactive or only available on request?
Some systems will produce an explanation if you ask for it. Better systems surface the reasoning as part of the normal workflow, so analysts aren't doing extra work to understand what happened. Our Assistant is built around this idea: it works conversationally, so users can ask "what does this signal mean?" or "are there any transactions of concern here?" and get an answer grounded in their specific data, not generic guidance. That's not a chatbot. It's a window into the decisions being made on the backend.
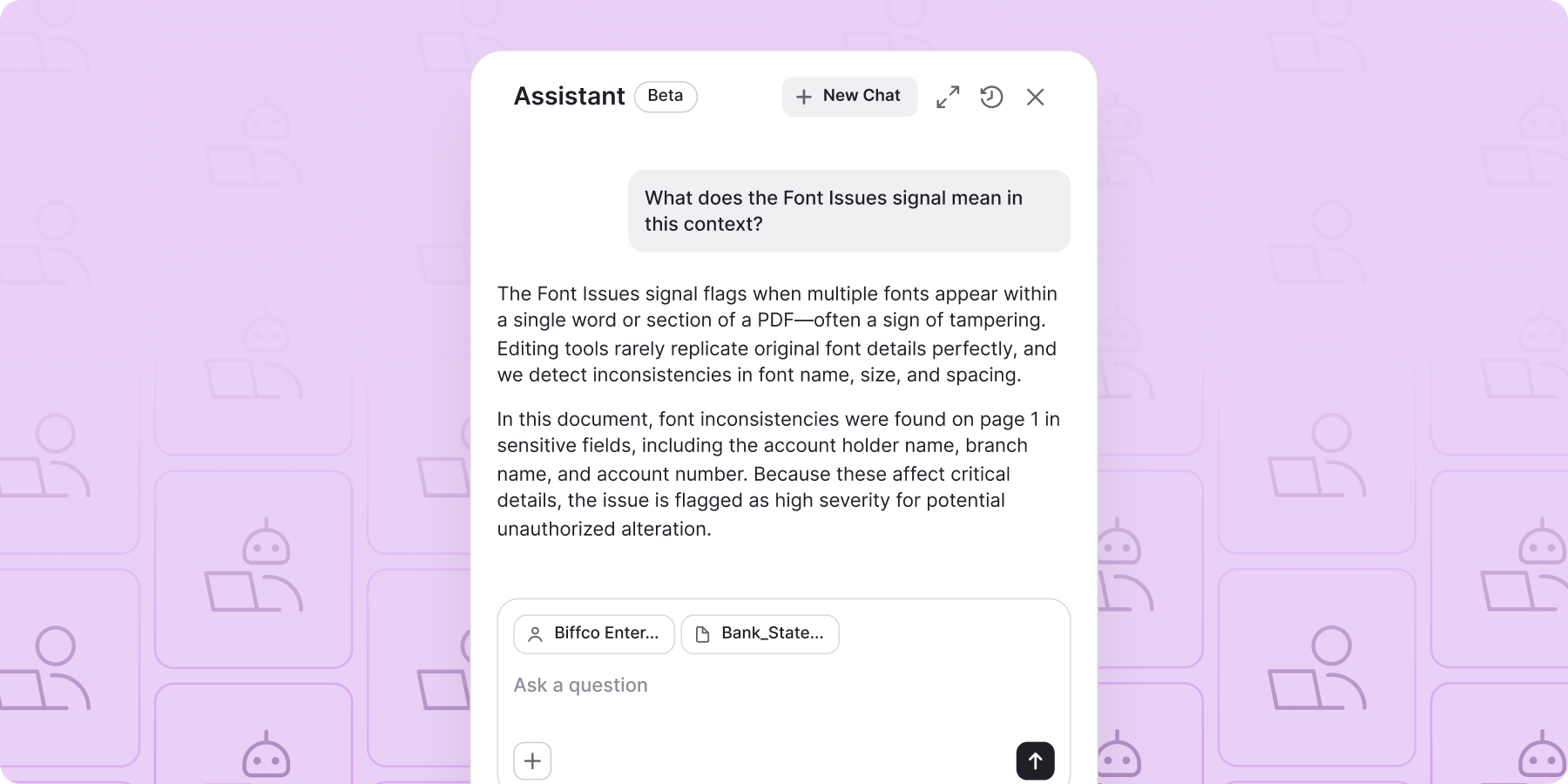
4. What happens when the AI is wrong?
Every system will make mistakes. What matters is whether the system's reasoning makes the mistake visible. If an analyst can follow the logic and identify where it broke down, the mistake becomes a learning opportunity. If the reasoning is opaque, the same mistake will keep happening.
Why explainability in fraud detection matters more now than ever
We know that document fraud is increasingly being generated by AI. Templates, generative models, and fraud-as-a-service tools have lowered the barrier to entry dramatically. According to Inscribe's 2026 State of Document Fraud Report, AI-generated document fraud increased nearly fivefold across our network between April and December 2025 alone.
Keeping up with that requires AI on the detection side, too. But the institutions that will have the most confidence in those systems are the ones that understand what they're buying. Not just "is it accurate?" but "can my team see what it's doing, explain the outcome, and act on it?"
Those are the questions that separate useful AI from trusted AI. And in fraud prevention, trust is the whole game.
If you're a bank, credit union, or lender interested in learning more about explainability, we're happy to chat. Book time with my co-founder Ronan here.
FAQs about explainable AI in fraud detection
What is explainable AI in fraud detection?
Explainable AI in fraud detection refers to systems that show the reasoning behind a decision, not just the outcome. Rather than returning a risk score alone, an explainable system surfaces the specific signals, observations, and logic that led to a conclusion. This makes decisions auditable, helps analysts learn from the system, and supports compliance documentation requirements.
Why does AI explainability matter for financial institutions?
Financial institutions make high-stakes, high-consequence decisions that must be defensible to regulators, auditors, and in some cases the applicants themselves. When AI flags a document as fraudulent or recommends rejecting an application, risk teams need to document why. A black box system that only returns a score creates a compliance gap and erodes analyst trust in the tool over time.
What is a black box AI system?
A black box AI system is one where the internal reasoning is not visible to the user. The system accepts inputs, processes them using models or rules that aren't exposed, and returns an output, typically a score or decision, without showing its work. In fraud detection, this means analysts can't verify whether a flag is accurate, can't learn from the system's findings, and can't produce documentation explaining the decision.
How is non-determinism in LLMs handled in fraud detection?
Large language models have a temperature parameter that controls how variable their outputs are. For fraud detection, this is typically set to zero, which means the system is configured for maximum consistency — given the same inputs, it is more likely to produce similar conclusions. Some variance at the infrastructure level is unavoidable with any large language model, but the effect is minimal and the reasoning remains logically stable across runs.
It's also worth separating this from a related but distinct point: an LLM's ability to generalize is a feature, not a liability. A reasoning model that doesn't simply pattern-match on previously seen cases is better equipped to catch new and evolving fraud types — and that capability comes from how the model was trained to reason, not from temperature. You can have both consistency at inference time and strong generalization. The two aren't in tension.
What questions should I ask an AI fraud detection vendor about explainability?
Start with four: Is there a human in the loop, or is the system making fully automated decisions? Can it produce audit-ready documentation for every decision? Is the reasoning surfaced proactively in the workflow, or only available if you ask for it? And what happens when the system is wrong? Can analysts follow the logic to identify where it broke down? Vendors who can answer these clearly are worth a closer look.
How does Inscribe approach explainability?
Inscribe's AI Agents are built to show their work. When analyzing a document, the system surfaces the specific signals it identified, the severity of each, and a plain-language summary of its reasoning. The Assistant lets analysts ask follow-up questions conversationally, getting answers grounded in their specific data rather than generic guidance. Every output is designed to be audit-ready and defensible.
About the author
Conor Burke is the co-founder and CTO of Inscribe, where he leads the AI and engineering systems behind the platform's document fraud detection capabilities. He writes and speaks on the technical mechanics of fraud detection — how LLMs reason, where rules-based systems break down, and what it actually takes to build AI that explains itself.
What will our AI Agents find in your documents?
Start your free trial to catch more fraud, faster.